![[Road to Carefree Life] Good bye 2025 !](/images/recap/road-to-carefree-life-2025.png)
[Road to Carefree Life] Good bye 2025 !
2025년 한 해를 돌아보는 첫 번째 회고 - 불확실한 문제를 구조로 정의하고, 그 구조를 실제 코드로 증명하는 개발자로 성장한 1년
시작하기 전에
올해는 내 인생에서 가장 빠르게 지나간 한 해인 것 같다.
스타트업에 왔다보니 확실히 이전보다 개인의 책임과 권한이 많아져 주도적으로 개발할 수 있는 일거리들이 많아서 바쁜만큼 즐겁게 개발할 수 있는 한 해 였던 것 같다.
업무를 떠나서도 개인적으로 시간을 내어 모교 캡스톤 멘토링 및 TSBM 밋업, AI SUMMIT, RAG 개발자 패널토크 등의 커뮤니티 활동과 TSBM 커뮤니티에서 알게된 Node.js 스터디에도 참여했다보니 더욱 시간이 빨리 가지 않았나 싶다.
그리고 올해 3월, 지인의 소개로 4년만에 다시 연애를 시작하게 되어 더 소중한 1년을 보낼 수 있었다. Shout out to MJ !
시간이 가는지도 모르고 어느새 2년차 개발자가 되었지만, 이제야 첫 회고를 작성하게 되었다.
이런저런 핑계를 대자면.. 하룻밤새 전 직장과 그룹사가 뉴스에 나오더니 월급이 밀리게 되었고.. 우리 가족 사정 상 내 월급이 없으면 안되기에 이직을 무조건 해야만 했다.
운이 좋게도 바로 플로우에 합격하여 이직을 할 수 있었고, 다사다난 했던 작년 이맘 때쯤엔 회사에 적응하기 바빠 다른 곳에 눈을 돌리지 못했던 것 같다.
사실 올해 지금은 작년보다도 더 바쁘고 정신없는 상황이지만, 현재 우리 팀의 리더인 유민호 실장님께서 과거에 분기마다 회고글을 작성하신 것을 보고 올해부터는 꼭 회고를 작성해보며 나를 돌아보기로 혼자만의 약속을 했다.
내 삶은 정해져 있는 트랙이 아니기 때문에, 속도만 올려 앞만보고 달려서는 내가 원하는 목적지에 도착할 수 있을지 모른다. 그래서 Sub Destination 을 나누어 그 끝마다 내가 달려온 길을 돌아보며 올바른 방향과 속도로 가고 있는지 회고를 통해 평가하고 다음 목적지로 출발하고자 Road to Carefree Life 회고 시리즈를 작성해나가려 한다.
2025년 - 나는 어떤 사람이었는가 ?
나는 어떤 아들이었는가 ?
나는 듬직한 아들이자 가장이다. 2023년 가을, 대학을 졸업하기도 전에 너무나도 갑자기 우리 가족을 먹여 살려야하는 책임이 생겼다. 올해도 마찬가지로 나는 부모님께 받아온 무조건적인 사랑에 무조건적인 사랑으로 답하고 있는 듬직한 아들로서 우리 가족을 지키고 있다.
나는 어떤 동료인가 ?
이건 평가를 받아야 할 것 같은데.. 부끄러우니 그냥 지극히 주관적인 내용과 평가를 기반으로 작성해봐야겠다. 올해는 정말 다양한 분들과 다양한 프로젝트에서 협업을 했다. 스타트업이라는 특수한 회사의 상황과 분위기도 있지만, 내가 잘 할 수 있는 분야에서 내 역량을 최대한 발휘하고 싶어 기회가 생길때마다 잡으려 했던 시도들 때문이기도 하다. 결과적으로는 여러 프로젝트에서 내 역할을 잘 수행했지만, 이를 동시에 진행하는 과정에서 한 동료분을 설득하지 못한 것 같다. 한 프로젝트를 진행하던 중 또 다른 프로젝트가 시작되었다. 사내 타 개발자 리소스가 없는 상황에서 나는 내 여가시간을 투자하여 해당 프로젝트도 병행하겠다고 리더분들께 제안했고, 흔쾌히 승낙되어 기존 프로젝트 수행에 차질이 없다고 생각되는 선에서 프로젝트를 병행하게 되었다. 하지만 나는 리더분들께 허가를 받아야 한다는 생각만 하고 이를 기존에 함께 프로젝트를 수행하던 동료분께 정확하게 인지시켜드리지 못했다. 개발이 재밌어서, 주말이나 퇴근 후에 사이드 프로젝트를 하며 힐링을 하곤 하는데 그냥 이 시간에 신규 프로젝트를 진행하면 일거양득이라고 생각하고 진행했으나, 이 내용을 충분히 동료분에게 인지시킨 후에 진행했었으면 어땠을까 하는 아쉬움이 다시 한번 남는다. 그 외의 아쉬움은 없는 것 같다. 플로우에서 다양한 분들과 친분을 쌓았고, 회사 밖에서는 형, 동생 할 만큼 공적으로나 사적으로나 친해진 분들도 이제 꽤 있다. 협업 과정에서 배울 수 있는 것들을 많이 배우려고 노력했고, 반대로 내가 도움을 줄 수 있는 부분에서 대신 업무 처리도 하고 의사결정해야 하는 상황에서 충분한 근거를 들어 설득해내곤 했다. 평소 어떤 것을 질문하기 전에 충분히 찾아본 후에 질문하는 것은 예의라고 생각하는데 이 태도 또한 좋은 평가 중 하나였던 것 같다. 동료 평가에서 "커뮤니케이션에 비용이 들지 않는 유일한 동료" 라는 평가도 기억에 남는 것 같다.
나는 어떤 남자친구인가?
올해도, 내년도, 앞으로도 배울 수 있는, 좋은 영향을 줄 수 있는 사람이 되고 싶다.
올해 나는 어떤 개발자였는가?
올해 나는 신규 서비스 개발과 기존 프로젝트의 고도화를 병행하며, 여러 개의 크고 작은 프로젝트를 동시에 수행했다. 대부분의 프로젝트는 누군가에게 배정받은 일이 아니라, 내가 직접 맡겠다고 요청해 시작된 작업이었다. 정답이 정해지지 않은 초기 단계의 문제를 마주하는 일이 부담스럽기보다는, 오히려 그 안에서 구조를 만들어가는 과정 자체를 즐겨왔기 때문이다. 신규 서비스를 여러 프로젝트 및 TFT 를 통해서라도 빠르게 출시하여 결과를 내야하는 상황에서, 회사가 나에게 요구한 역할 또한 그것이라고 생각된다.
기능을 구현할 때 나는 항상 “이 기능은 왜 지금 이 형태여야 하는가” 를 먼저 고민한다.
단순히 요구사항을 충족하는 구현보다, 이 선택이 이후의 확장과 변경에 어떤 영향을 미칠지를 더 중요하게 본다.
그래서 하나의 기능을 설계할 때도 여러 대안 구조를 비교하고, 각 선택이 가져올 트레이드오프를 충분히 검토한 뒤 결정을 내린다.
이런 방식으로 구현된 코드에 대해서는, 동료들로부터 “그 구현에는 분명한 이유가 있을 것” 이라는 신뢰를 받고 있다.
나는 전체 구조를 먼저 그린 뒤 세부 구현으로 내려오는 방식을 선호한다.
파일과 모듈의 역할을 명확히 나누고, 함수와 상수는 재사용 가능한 단위로 분리하며, 확장성과 유연성을 해치지 않는 방향으로 코드를 구성하려고 노력한다.
클린 코드, 헥사고날 아키텍처, FSD와 같은 설계 방식에 관심을 갖는 것도 결국 “지금의 편의보다, 이후의 변화에 강한 구조를 만들고 싶은 욕심” 때문이다.
또한 본격적인 개발에 앞서, 기술적 가능성을 빠르게 검증하기 위한 프로토타입을 만드는 방식을 자주 사용했다. 짧은 시간 안에 실제로 동작하는 형태를 만들어보고, “된다 / 안 된다”를 명확히 판단한 뒤에야 본 개발에 들어갔다. 여가 시간에 진행한 실험이나 R&D 결과가 실제 서비스 기능으로 이어진 경험도 여러 번 있었고, 이를 통해 기술적 상상과 제품 현실 사이의 간극을 줄이는 역할을 해왔다.
최근에는 AI를 단순한 코드 생성 도구가 아니라,
사고를 정리하고 설계를 검증하는 협업 파트너로 활용하고 있다.
구현 전에 코드베이스를 기준으로 직접 전체 계획을 먼저 설계하고, 이를 명확한 텍스트로 정리해 AI와 검증한다.
이를 통해 개발 건에 대한 컨텍스트를 AI 와 공유 및 유지하려고 노력한다.
하나의 커밋을 만들기 전에도 코드 규약, 컨벤션, 포맷팅을 점검하고, 구조적 관점에서 다시 한 번 냉정한 평가를 거친 뒤 반영한다.
(Claude Code 사용할 때 "냉정하게 평가해줘" 라고 하면 확실히 날카롭게 변경사항과 코드베이스를 분석하고 더 정밀한 평가를 해주는 것 같아 요즘 자주 사용하고 있다.)
올해 나는 특정 기술 하나를 깊게 파는 전문가라기보다는, 백엔드 / 프론트엔드를 넘나들며 여러 신규 서비스의 구조와 흐름을 책임지는 역할을 반복했다.
그리고 이 과정에서,
불확실한 문제를 외면하지 않고 끝까지 파고들며 “지금 가장 합리적인 구조는 무엇인가” 를 고민하는 개발자로 성장하게 된 올해인 것 같다.
2025 년도의 나는: "불확실한 문제를 구조로 정의하고, 그 구조를 실제 코드로 증명하는 개발자"
2025년 - 나는 어떤 문제를, 어떤 방식으로, 어떤 수준에서 해결해 왔을까 ?
올해를 관통하는 핵심 테마 3가지
1. 정답이 없는 문제를 구조화하여 정의하다
올해 내가 가장 많이 맡아온 역할은,
요구사항이 완전히 정리되지 않은 상태에서 “무엇을 만들어야 하는지”부터 함께 정의하는 일이었다.
기획이 충분하지 않거나 정답이 정해지지 않은 상황에서 요구사항을 그대로 구현하기보다는,
이 문제가 어떤 구조와 흐름을 가져야 하는지를 먼저 고민했다.
여러 신규 서비스 개발을 진행하며, 나는 0에서 1을 만드는 과정에 반복적으로 참여했다.
이 과정에서 요구사항은 종종 불완전했고, 구현보다 먼저 문제의 경계를 나누고 책임을 정의하는 일이 필요했다.
어떤 기능이 핵심이고, 어떤 변화가 구조 안에서 흡수되어야 하는지,
그리고 지금은 구현하지 않더라도 구조 설계를 통해 대비해 두어야 할 지점이 무엇인지에 집중했다.
기능 하나를 설계할 때도 “이 방식이 왜 지금 상황에서 가장 합리적인가” 를 설명할 수 있어야 한다고 생각했다.
그래서 단순히 동작하는 코드를 만드는 데서 멈추지 않고, 대안 구조와의 차이, 선택하지 않은 이유까지 정리하며 구현을 진행했다.
이런 과정 덕분에, 내가 구현하거나 리팩토링한 기능에 대해서 구현 방식 자체에 대한 신뢰가 자연스럽게 형성되었다.
이 경험을 통해 나는 주어진 요구사항을 빠르게 처리하는 개발자에서,
문제의 구조를 정의하고 그 선택에 책임을 지는 개발자로 역할이 바뀌고 있음을 느꼈다.
기술 스택이나 특정 구현 방식보다,
문제를 어떻게 정의하느냐가 결과의 품질을 좌우한다는 것을 올해의 경험을 통해 분명히 체감하게 되었다.
2. 빠르게 검증하고, 확신이 생긴 뒤 깊게 들어간다
팀 내에서 새로운 방향이나 문제 정의를 두고 오랜 고민과 논의를 이어가도 명확한 결론에 이르지 못하는 상황이 자주 있었다. 그럴 때마다 리더가 나에게 했던 요청은 늘 비슷했다. “실제로 동작하는 형태를 빠르게 만들어 올 수 있겠는가. 그걸 보고 한 번 결론을 내보자.”
이 경험을 반복하며, 나는 가능성을 말로 설명하거나 논쟁하기보다 짧은 시간 안에 실제로 동작하는 결과물을 통해 판단의 근거를 만드는 역할을 맡게 되었다. 완벽한 설계를 충분히 고민한 뒤 움직이는 것도 좋지만, 때론 빠른 검증을 통해 방향성을 좁혀가는 방식이 조직과 프로젝트에 더 효과적이라는 것을 몸으로 익히게 되었다.
새로운 기능이나 기술을 도입할 때도 곧바로 본 구현에 들어가기보다는, 최소한의 형태로 프로토타입을 먼저 만들었다.
이를 통해 기술적 제약이나 예상치 못한 병목을 조기에 드러내고, “된다 / 안 된다”를 빠르게 판별했다.
이 과정은 불필요한 구현을 줄이고, 팀의 시간과 리소스를 아끼는 데 중요한 역할을 했다.
여가 시간에 진행한 개인적인 R&D 역시 단순한 실험에 그치지 않고, 실제 서비스에 적용 가능한 수준까지 발전시키는 데 집중했다. 직접 구현한 결과를 팀에 공유하고 시연하면서, 아이디어의 가능성을 말이 아닌 코드로 설명했고, 그중 일부는 실제 프로덕트의 기능으로 이어졌다.
여러 프로젝트를 동시에 병행해야 했던 환경에서도 이 방식은 특히 효과적이었다.
모든 것을 완벽히 이해한 뒤 움직이려 하기보다, 작게 만들고 빠르게 검증하면서 방향을 좁혀나갔기 때문에
속도를 잃지 않으면서도 판단의 정확도를 유지할 수 있었다.
이 경험을 통해 나는 완벽한 설계에 집착하던 개발자에서, 검증을 통해 의사결정을 가능하게 만드는 개발자로 사고 방식이 확장되었다. 확신 없는 상태에서 시간을 쌓는 것보다, 작은 시도를 통해 빠르게 근거를 만들고 그 위에서 깊이를 더하는 것이 때론 실무에서 훨씬 강력한 전략임을 올해의 경험을 통해 체득했다.
3. 코드를 기능이 아니라 ‘자산’으로 만들다
여러 프로젝트를 동시에 진행하고, 신규 서비스 개발과 고도화를 반복하면서
나는 코드가 단순히 “지금 동작하는 결과물”로 남아서는 안 된다는 생각을 점점 더 강하게 하게 되었다.
당장의 요구사항을 빠르게 충족하는 것은 당연한 전제였고,
그 과정에서 이 코드가 이후의 변화와 확장을 얼마나 견딜 수 있는지까지 함께 고민했느냐에 따라
프로젝트 전체의 속도와 안정성이 달라진다고 느꼈기 때문이다.
그래서 기능을 구현할 때도 개별 로직을 빠르게 추가하는 방식보다는, 확장 가능성을 고려해 구조를 먼저 정리하는 데 많은 시간을 썼다. 역할과 책임이 명확하게 드러나도록 파일과 모듈을 나누고, 공통으로 사용될 가능성이 있는 로직은 의도적으로 분리했다. 이 선택은 당장은 구현 속도를 늦추는 것처럼 보일 수 있었지만, 요구사항이 늘어날수록 오히려 전체 수정 비용을 낮추는 결과로 이어졌다.
또한 코드의 품질을 개인의 취향으로 남기지 않기 위해 컨벤션과 포맷, 커밋 단위까지 신경 쓰는 습관을 유지했다.
코드는 혼자만 이해하면 되는 결과물이 아니라,
팀이 함께 읽고 수정하며 오래 가져가야 할 자산이라고 생각했기 때문이다.
클린 코드나 헥사고날 아키텍처, FSD와 같은 설계 방식에 관심을 가져온 것도 특정 방법론을 따르기 위해서라기보다,
역할과 경계를 명확히 드러내는 구조를 만들기 위한 고민의 연장선이었다.
이 과정에서 AI 역시 단순히 코드를 대신 작성해주는 도구가 아니라,
내가 세운 설계와 구조를 검증하는 파트너로 활용했다.
구현에 들어가기 전에 계획을 명확히 정리하고, 코드 규약과 구조적 관점에서 다시 한 번 점검한 뒤 반영함으로써
한 번 만들어진 코드가 쉽게 무너지지 않도록 관리했다.
이 과정을 통해 나는 “작동하는 코드”를 만드는 개발자에서,
시간이 지나도 유지되고 축적되는 시스템을 만드는 개발자로 사고가 확장되었다.
코드 품질은 개인의 만족이나 취향의 문제가 아니라, 팀의 생산성과 서비스의 지속성을 결정짓는 중요한 자산이라는 인식을 올해의 경험을 통해 분명히 갖게 되었다.
올해 수행한 프로젝트
FLOKR - 대기업 보험사의 OKR 성과 관리 시스템
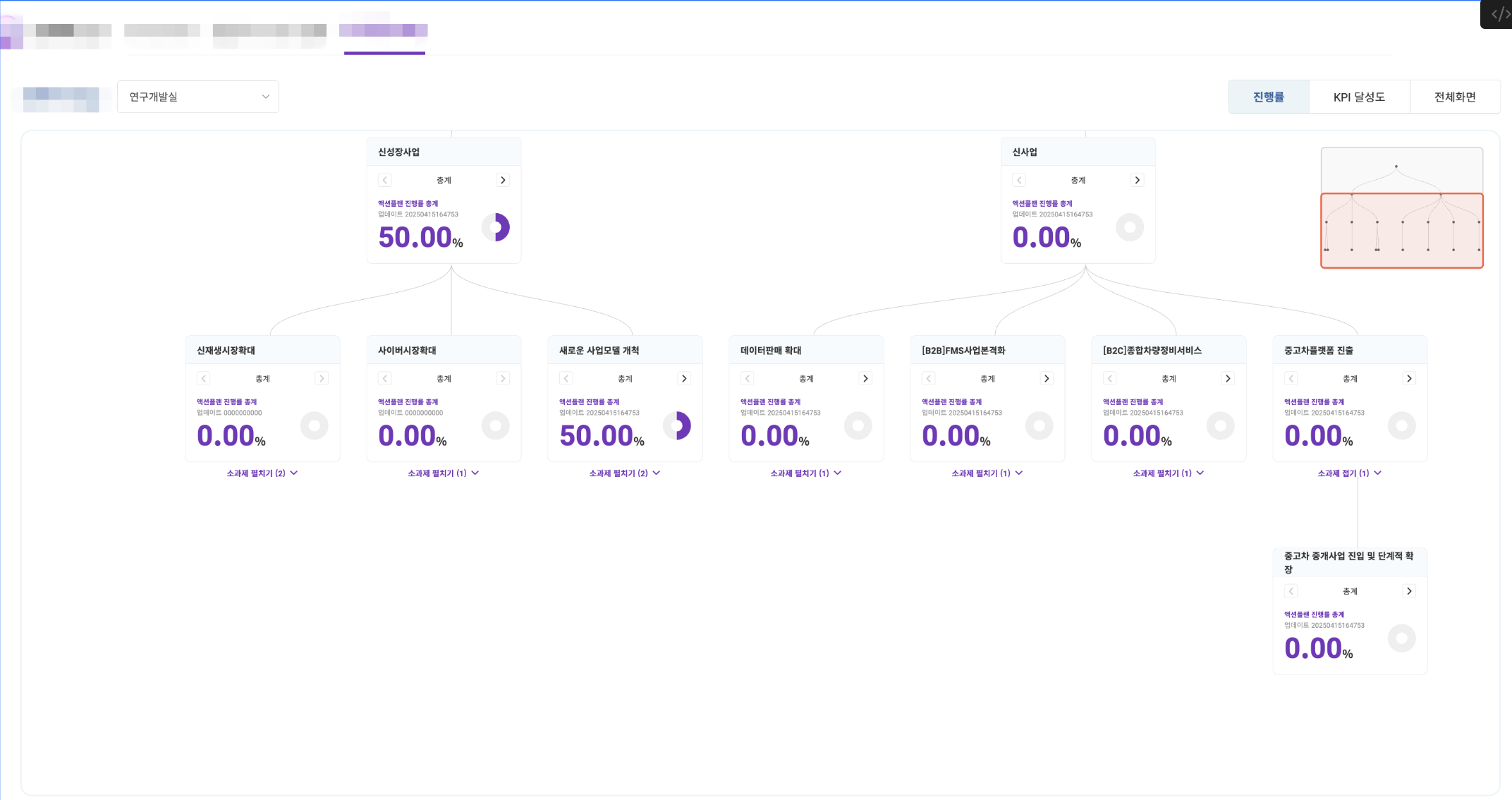
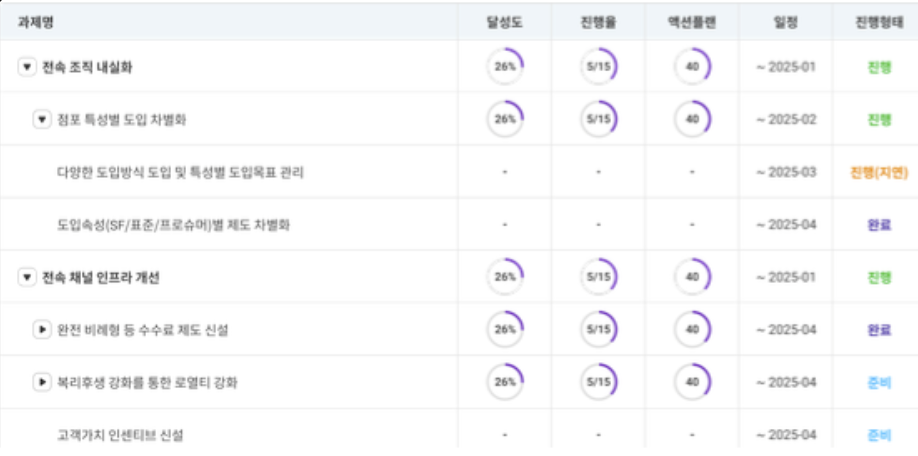
올해를 시작했던 첫 프로젝트이자 플로우 입사 후 첫 신규 개발건이다. 대기업 보험사에서 기존 엑셀 기반의 OKR 관리를 벗어나, 수만 명 직원의 부문/부서별 성과를 한눈에 시각화하고 싶다는 요구가 있었다.
나는 이 프로젝트에서 백엔드 전체 설계/구현과 프론트엔드 전체, 특히 OKR Map 시각화를 담당했다. "사람의 업무 흐름을 코드로 표현한다"는 관점에서 접근해야 했던 프로젝트였는데, 추상적인 OKR 개념(목표-핵심결과)을 과제(Task) - 액션플랜(ActionPlan) - KPI라는 계층 구조로 모델링하고, 이를 d3.js 기반의 인터랙티브한 트리 다이어그램으로 시각화하는 것이 핵심 도전이었다.
기술적으로 가장 기억에 남는 부분은 트리 구조 생성 시 N+1 쿼리 문제 해결이다.
부문별로 수백 개의 노드를 처리해야 했는데, 각 Task마다 하위 ActionPlan과 KPI를 개별 조회하면 성능이 급격히 저하되었다.
이를 In() 연산자를 활용한 배치 쿼리 패턴으로 해결하고, Redis 캐싱 인터셉터까지 도입해 응답 속도를 크게 개선했다.
아키텍처 측면에서는 흥미로운 전환이 있었다. 초기에 헥사고날 아키텍처(CQRS 패턴)로 시작했지만, 프로젝트 규모 대비 과도한 복잡성과 팀원들의 러닝커브 문제로 레이어드 아키텍처로 전환했다. "적정 기술"의 중요성을 몸소 체감한 경험이었다. 완벽한 설계보다 동작하는 시스템, 그리고 팀이 함께 유지보수할 수 있는 구조가 더 중요하다는 것을 배웠다.
프론트엔드는 퍼블리싱 팀과의 협업 제약으로 VanillaJS를 사용해야 했다. React가 아닌 환경에서 d3.js의 foreignObject 를 활용해 복잡한 카드 UI를 SVG 안에 삽입하고, 미니맵 네비게이션과 줌/팬 인터랙션까지 구현하는 과정은 쉽지 않았지만, 그만큼 성장할 수 있었다.
AI TFT 수행을 위해 인수인계 후 현재 고객사 운영 중인 상태다.
FLOWIKI - 사내 위키 및 실시간 협업 문서 시스템
이 프로젝트는 FLOKR을 진행하던 중 시작된 신규 프로젝트였다. 앞서 "동료를 설득하지 못했다"고 언급했던 그 프로젝트가 바로 FLOWIKI다. 사내 개발자 리소스가 부족한 상황에서 내 여가시간을 투자해 병행하겠다고 제안했고, 약 2개월간 초기 개발을 담당했다.
FLOWIKI는 Notion이나 Confluence 같은 외부 도구 의존도를 줄이고, 사내 지식을 체계적으로 관리할 수 있는 실시간 협업 문서 시스템이다. 나는 프론트엔드 초기 아키텍처 설계와 Full Text Search 백엔드를 담당했다.
이 프로젝트에서 가장 의미 있었던 경험은 초기 개발만 담당했음에도 실제 엔터프라이즈 고객사에서 운영되는 서비스의 기반을 설계했다는 점이다. Next.js App Router, TipTap 에디터, Zustand 상태 관리 등 기술 스택을 직접 선택하고, 이후 확장을 고려한 구조를 설계했다.
기술적으로는 PostgreSQL Full Text Search 한글 처리가 가장 도전적이었다.
한글은 영어와 달리 형태소 분석이 필요하고, 조사와 어미 처리가 복잡하다.
to_tsvector('korean', ...) 과 to_tsquery('korean', ...) 를 활용해 한글과 영어를 동시에 검색할 수 있도록 구현했고,
파라미터 바인딩을 통해 SQL Injection 방어도 철저히 했다.
또한 계층형 사이드바의 재귀적 트리 렌더링 성능 최적화, Zustand persist 미들웨어를 활용한 탭 상태 유지 등 실제 사용자 경험을 고려한 세부 구현들을 직접 해결해나갔다.
현재 FLOWIKI는 SK 쉴더스, 매그나칩 반도체 등 엔터프라이즈 고객사와 플로우 SaaS에서 운영 중이다. 초기 개발만 담당하고 운영은 다른 분께 인수인계했지만, 내가 설계한 구조 위에서 서비스가 확장되어 실제 고객들이 사용하고 있다는 사실이 뿌듯하다.
두 프로젝트를 통해 배운 것
FLOKR과 FLOWIKI, 성격이 전혀 다른 두 프로젝트를 동시에 진행하면서 나는 "문제의 본질을 파악하고 구조로 정의하는 능력" 이 가장 중요하다는 것을 깨달았다.
FLOKR에서는 "사람의 업무 흐름을 어떻게 코드로 표현할 것인가"를, FLOWIKI에서는 "사용자가 정보를 어떻게 찾고 정리하는가"를 고민해야 했다. 기술 스택은 달랐지만, 결국 도메인을 깊이 이해하고 그에 맞는 구조를 설계하는 과정은 동일했다.
또한 두 프로젝트 모두 **"적정 기술"**의 중요성을 가르쳐줬다. FLOKR에서의 헥사고날 → 레이어드 전환, FLOWIKI에서의 RediSearch 대신 PostgreSQL FTS 선택 등 화려한 기술보다 상황에 맞는 합리적인 선택이 프로젝트의 성공을 좌우한다는 것을 체감했다.
flow AI
FLOKR과 FLOWIKI를 통해 "구조화"와 "적정 기술"이라는 두 가지 키워드를 체득한 나에게, 2025년 6월, 전혀 예상하지 못한 미션이 주어졌다. AI TFT — 회사의 핵심 프로덕트가 될 AI 서비스를 처음부터 만드는 태스크포스였다. 2년차 백엔드 개발자가 한 번도 다뤄본 적 없는 AI 도메인으로 뛰어드는 것. 솔직히 두려웠지만, 기획부터 설계, 개발까지 End-to-End로 참여하는 첫 번째 경험이라는 사실에 설렘이 두려움보다 컸다.
그렇게 시작된 8개월의 여정은, 내 개발자 커리어에서 가장 밀도 높은 시간이 되었다.
시작 — 2025년 6월
6월 16일, 대표님과의 첫 회의가 있었다. 대표님은 노키아와 코닥을 언급하며 "시대의 흐름을 놓치면 안 된다" 고 말씀하셨다. AI는 더 이상 선택이 아니라 필수이고, 기존 flow 플랫폼 위에 기능을 얹는 수준이 아니라, 완전히 새로운 프로덕트를 만들어야 한다는 것이 핵심 메시지였다. "Mate X (초기 서비스 명) 는 완전히 새로운 프로덕트이다" 이 한 문장이 이후 8개월의 방향을 결정지었다.
새로운 프로덕트의 기획 단계부터 참여하는 것은 개발자로서 처음이었다. 무엇을 만들어야 하는지조차 명확하지 않은 상태에서 기술 스택을 선택하고, 아키텍처를 설계해야 한다는 사실이 막막하면서도 흥분되었다. 그리고 6월 30일, 첫 커밋을 올렸다.
배움의 시기 — 7월~8월
7월은 문자 그대로 매일이 새로운 개념과의 싸움이었다.
LangChain 공식 문서를 펼쳐놓고 Tool Calling 예제를 따라 치는 것부터 시작했다.
bindTools()로 LLM에 도구를 접합하고, Zod Schema로 Tool의 입출력을 정의하는 법을 배웠다.
NestJS 컨트롤러에서 LLM을 호출하는 첫 번째 프로토타입을 만들었을 때,
모델이 내가 정의한 Tool을 스스로 선택하고 arguments를 채워 응답하는 것을 보며 소름이 돋았다.
"이게 되는구나" — 그 순간의 감각이 이후의 모든 삽질을 견디게 해주었다.
한 달 동안 120개의 커밋을 올렸다. AI 도메인의 기초 체력을 만드는 시간이었다.
8월에는 RAG 기반 AI 비서(Assistant) 개발이 본격화되었다.
RAG라는 기술을 처음 접했을 때, 개념은 이해가 되었지만 실제 구현은 전혀 다른 차원의 문제였다.
OpenAI에서 제공하는 Assistant API를 먼저 사용해보며 RAG의 작동 원리를 직접 체감해보기도 하고,
여러 컨퍼런스와 RAG 개발자 커밋에 참가하며 실무자들의 경험을 흡수했다.
그 과정 끝에 pgvector로 벡터 검색을 구현하고, 문서 임베딩 파이프라인을 구축할 수 있게 되었다.
가장 고통스러웠던 것은 출처 하이라이팅이었다.
AI가 참조한 원문의 정확한 위치를 브라우저에서 하이라이팅해야 했는데, 같은 PDF 내에서 같은 청크의 서로 다른 문장을 각각 표시해야 하는 상황, HTML DOM 구조가 원본 문서와 미묘하게 달라지는 문제 등
새벽 2시까지 DOM을 뒤지며 정확한 하이라이팅 로직을 구현했던 밤들이 기억난다.
177개의 커밋. RAG라는 기술을 "들어본 것"에서 "직접 파이프라인을 구축한 것"으로 바꾼 한 달이었다.
폭발적 성장 — 9월
9월은 프로젝트 전체 기간 중 가장 밀도 높은 달이었다. 한 달에 299개의 커밋 — 단순히 양이 많았던 것이 아니라, AI 비서와 일반 채팅이라는 두 축이 동시에 성장하던 시기였다.
AI 비서 쪽에서는 안정화 작업이 한창이었다. 메시지별로 출처를 저장하는 구조를 만들고, QueryAnalysis 노드를 추가하여 사용자의 질문이 단순 조회인지 벡터 검색이 필요한지를 AI가 먼저 판단하도록 했다. 프론트엔드에서는 출처 상태를 chip으로 관리하고, 참조한 원본의 존속 여부를 표시하며, 카드 클릭 시 모달에서 하이라이팅된 위치로 자동 스크롤하는 등 세부 UX를 다듬어 나갔다.
동시에 일반 채팅의 첫 번째 구조가 만들어졌다.
LangGraph의 StateGraph를 사용하여 입력 분석, 모델 선택, 보안 마스킹, 스트리밍 등
6개 노드로 구성된 GeneralChatWorkflow 가 구현되었다.
당시에는 이 구조가 나중에 완전히 뒤엎어질 줄 몰랐지만,
이런 워크플로우를 설계하고 운영해본 경험이 있었기에 11월의 결단이 가능했다.
이 시기에 API 40%, Front 51%이라는 프로젝트 소스코드 내 나의 비중이 자리 잡았다. 백엔드와 프론트엔드를 동시에 넘나드는 풀스택 개발 패턴이 내 작업 방식으로 굳어진 시점이다.
위기와 돌파 — 10월
10월에는 예상치 못한 위기가 찾아왔다. AI 응답의 실시간 마크다운 렌더링에서 브라우저 CPU 부하가 70~90%까지 치솟는 현상을 발견했다. 사용자가 AI와 대화하는 동안 브라우저가 사실상 멈추는 수준이었다.
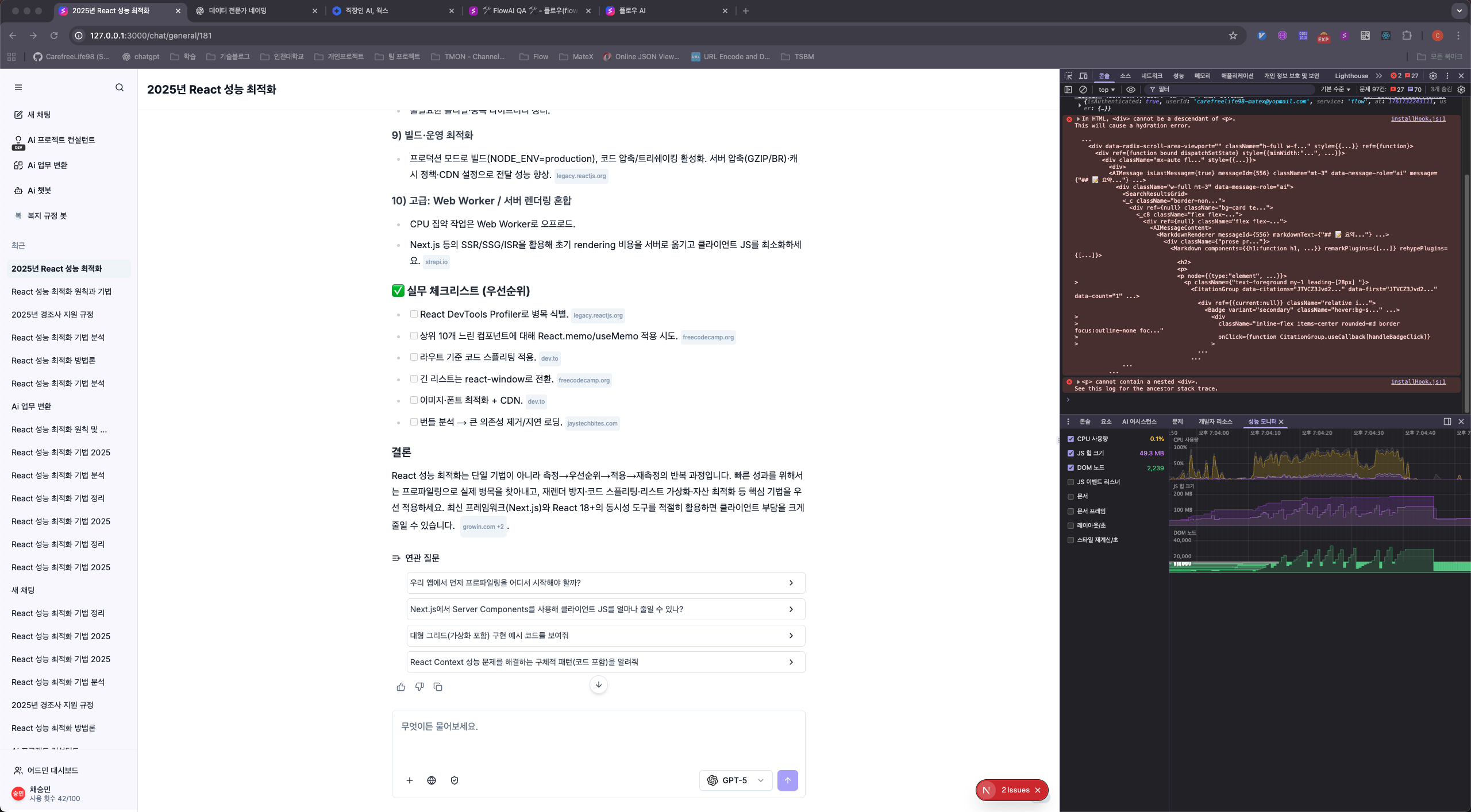
원인을 추적하기 위해 Chrome DevTools의 Performance 탭에서 Flame Chart를 분석했다.
문제의 핵심은 react-markdown이었다.
SSE 스트리밍으로 전달되는 청크 하나하나마다 전체 마크다운을 파싱하고, React Virtual DOM을 재생성하며, 전체 DOM 트리를 리렌더링하고 있었다.
한 번의 AI 응답에 수백 번의 풀 리렌더링이 일어나는 구조였던 것이다.
6단계에 걸친 체계적 성능 분석 끝에 하이브리드 렌더링 방식을 설계했다.
스트리밍이 진행되는 동안에는 marked.js를 사용하여 마크다운을 HTML 문자열로 변환한 뒤 innerHTML로 직접 주입하는 가벼운 방식을 사용하고,
스트리밍이 완료된 후에야 이벤트 핸들러가 붙은 완전한 react-markdown 컴포넌트로 전환하는 구조였다.
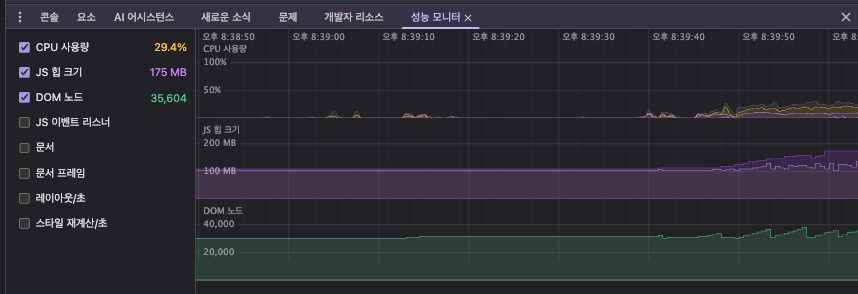
결과는 극적이었다. CPU 부하 70-100%가 20-30%로, FPS는 20에서 55로 개선되었다. 이 과정을 1,675줄짜리 성능 최적화 보고서로 직접 정리했었는데, 문제를 발견하고 → 원인을 측정하고 → 가설을 세우고 → 해결책을 설계하고 → 결과를 검증하는 엔지니어링 사이클 전체를 처음으로 체계적으로 경험한 순간이었다.
"작동하는 코드"와 "잘 작동하는 코드" 사이에는 측정과 분석이라는 거대한 간극이 있었다.
아키텍처 전환점 — 11월
11월은 flow AI 개발 8개월 중 가장 중요한 전환점이었다. 이전까지 만들어온 일반 채팅 시스템의 구조적 한계를 정면으로 직시해야 했기 때문이다.
기존 GeneralChatWorkflow는 모든 기능이 오직 시스템 프롬프트에 의해서만 정의되고 수행되고 있었다.
웹 검색, 이미지 생성, 코드 작성 등의 기능을 추가할 때마다
시스템 프롬프트가 비대해지고, 6개 노드가 하드코딩된 StateGraph의 복잡도는 기능 수에 비례하여 폭발했다.
패치를 거듭할수록 전체 시스템의 예측 가능성이 떨어지는 것이 느껴졌다.
나는 이 문제를 해결하기 위해 850줄짜리 채팅 도메인 공통화 설계 문서를 작성했다.
기존 시스템의 AS-IS 아키텍처를 노드 하나하나 전부 재분석하고, TO-BE 아키텍처를 근본부터 다시 설계하는 작업이었다.
단순한 리팩토링이 아니라 LangChain/LangGraph v1으로의 완전한 마이그레이션을 결정했다.
새로운 아키텍처의 핵심은 Main Agent + Sub Agent 구조였다.
createReactAgent API를 기반으로 Main Agent를 구현하고,
웹 검색, 이미지 생성, 프로그래밍, 플로우 데이터 검색 등 전문 영역은 각각의 Sub Agent에게 위임하는 방식이었다.
기능 추가가 시스템 프롬프트의 비대화가 아니라 새로운 Sub Agent의 등록으로 이루어지는 구조, 이것이 확장 가능한 에이전트 시스템의 핵심이었다.
동시에 AgentMiddlewareBuilder 패턴을 도입했다.
toolCallLimitMiddleware, modelCallLimitMiddleware, todoListMiddleware 등 횡단 관심사를 조합 가능한 미들웨어로 분리하고,
shouldDeepThink 플래그에 따라 Deep Think 모드를 조건부로 활성화하는 등 유연한 실행 파이프라인을 설계했다.
AgentEventSender 를 통해 Main Agent와 Sub Agent의 동시 스트리밍을 하나의 SSE 이벤트 체계(start, delta, tool_call_start, tool_call_stream, complete, error)로 통합한 것도 이 시기의 성과다.
4개의 서브 에이전트가 동시에 동작하며 각각의 스트리밍이 실시간으로 프론트엔드에 전달되는 것을 처음 확인했을 때, 소름이 돋았다.
9월에 만든 GeneralChatWorkflow를 완전히 갈아엎는 결정이었지만, 그 코드를 운영해본 경험이 있었기에 무엇이 문제이고 무엇이 필요한지를 정확히 알 수 있었다.
동작하는 코드를 부수는 것은 용기가 필요한 일이다.
완성의 시기 — 12월~1월
11월에 새로운 아키텍처의 뼈대를 세웠다면, 12월과 1월은 그 위에 살을 붙이는 시간이었다.
가장 도전적이었던 것은 Flow Search — flow 내부 데이터 의도 검색 기능이었다. 사용자가 자연어로 "지난주 마케팅팀 회의에서 결정된 사항이 뭐였지?"라고 물으면, flow 플랫폼 내의 프로젝트, 업무, 게시물, 채팅, 파일 등에서 관련 정보를 찾아 응답하는 시스템이다.
타 팀에서 기존에 구현한 AI 검색 기능이 있었지만, "검색 결과 유효성이 너무 낮고, 오류가 잦으며, 너무 느리다"는 고객·내부 임직원·대표님의 피드백이 이어졌다. 사용량을 보면 그 맥락이 조금 더 잘 보인다. 기존 검색은 10월에 약 2,500건 수준으로 사용되다가, 11월 489건, 12월 33건으로 점차 줄어들고 있었다. 수치가 정확하진 않더라도, 방향은 분명했다.
전면 재개발이 결정되었고, 당시 LangChain/LangGraph 생태계를 가장 깊이 다루고 있던 내게 그 작업이 맡겨졌다.
원인을 분석하니 명확했다. 전체 데이터를 대상으로 RAG를 수행하고 있었고, LLM이 과도하게 개입하는 구조였다. 나는 이를 의도 기반 검색 파이프라인으로 전면 재설계했다.
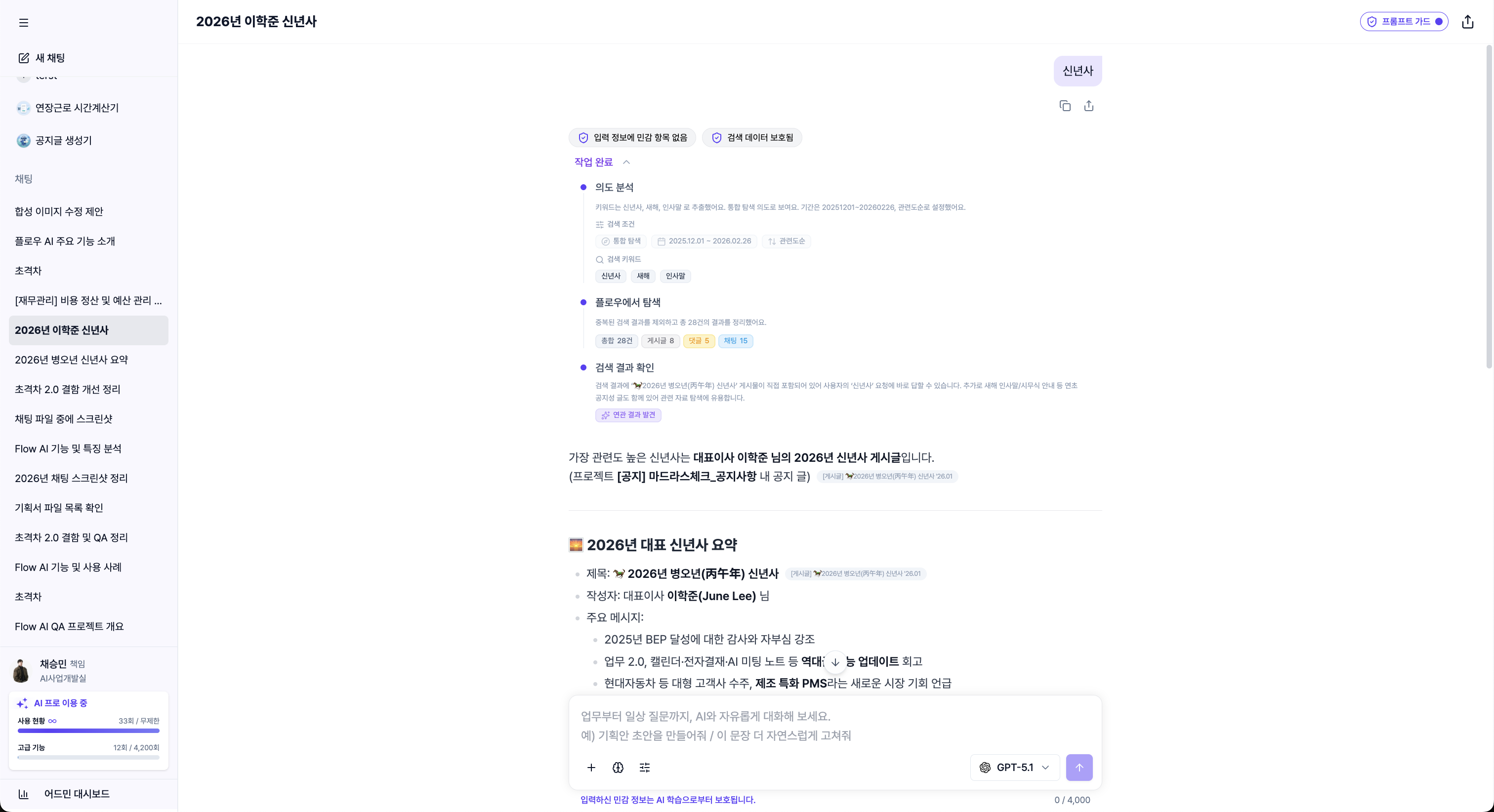
LangGraph StateGraph 기반의 7노드 파이프라인을 설계했다.
쿼리 분석(LLM) 노드 에서 사용자 의도와 검색 대상을 파악하고,
의도 매핑(규칙 기반) 노드 에서 설정 기반 API 세트를 선택하며,
검색 파라미터 구성 노드 에서 LLM이 최적화된 API 파라미터를 구성하고,
검색 실행 노드 에서 flow의 여러 검색 API를 병렬로 호출하며,
결과 병합 → 콘텐츠 필터 → 검증 단계를 거쳐 품질을 보장하는 구조다.
빠른 속도를 위해 LLM은 쿼리 분석과 검증 두 노드에만 사용하고, API 매핑·실행·병합은 규칙 기반·병렬로 처리했다.
특히 검증에 실패했을 때 의도 매핑을 건너뛰고 검색 파라미터 구성 노드부터 재시도하며 키워드를 확장하고, 날짜 범위를 넓히는 제어된 재시도 전략이 핵심이었다. 단순히 "검색 결과 없음"을 반환하는 것이 아니라, 파이프라인이 스스로 검색 전략을 조정해가며 최선의 결과를 찾아내는 과정을 구현했다.
또한 프로젝트가 특정되는 경우에는 RAG 도 함께 수행해 검색 유효성을 추가로 높였으며, 각 노드의 진행 상태를 SSE로 실시간 전달해 사용자가 검색 과정을 눈으로 확인할 수 있도록 UX도 개선했다.
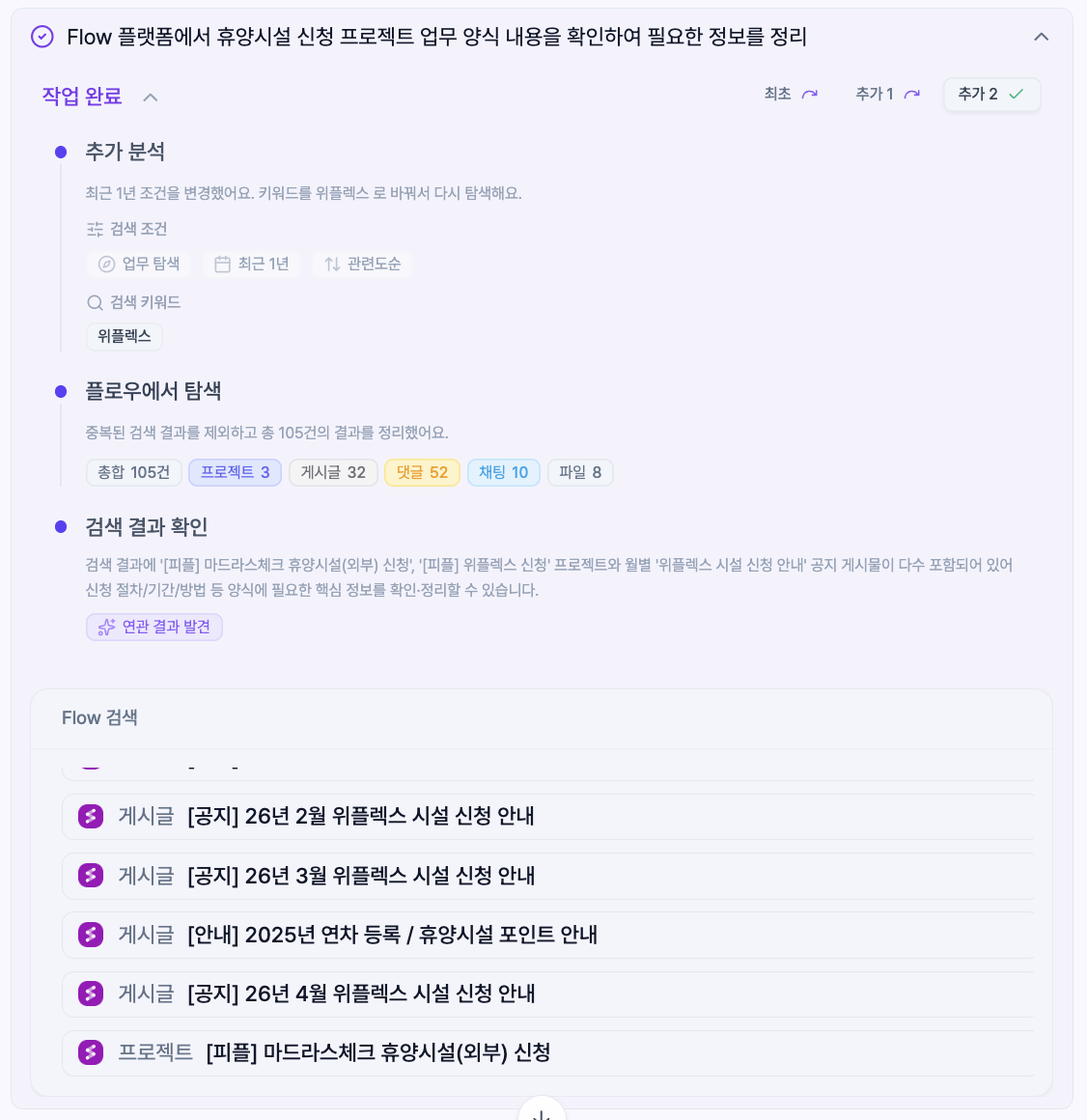
무엇보다 이 Flow Search 그래프를 일반 대화, 챗봇(RAG 비서), 에이전트, 부모 서비스인 flow 내부 임베드(iframe/웹뷰) 등 서비스 전 영역에서 동일하게 재사용할 수 있도록 유연하게 설계한 것이 이후 핵심 자산이 되었다.
AI 비서도 v2로 진화했다. RAG 기반 답변 생성에 문장 단위의 출처 표기를 고도화하여, AI가 어떤 문서의 어떤 부분을 참조하여 답변했는지를 사용자가 정확히 확인할 수 있게 했다.
인프라 측면에서도 중요한 기반 작업들이 이루어졌다. 대화 메모리는 20개 메시지 단위로 배치 요약을 생성하되 최근 10개 메시지는 항상 유지하는 증분 요약 전략으로 토큰 한도와 컨텍스트 풍부함 사이의 균형을 맞추었다. 이미지(Vision/OCR), PDF, Excel, HWP 등 다양한 파일 포맷의 컨텍스트를 사용자 메시지에 통합하는 파이프라인도 이 시기에 완성되었다.
런칭 — 2월
2월 초까지 마지막 안정화 작업이 이어졌다. Deep Think 모드를 최종 완성했다.
사실 Deep Think는 나의 개인 R&D에서 시작된 기능이었다. LangChain v1이 출시되며 함께 런칭된 Deepagents 라이브러리를 보고, 개인 시간에 에이전트 오케스트레이션을 직접 만들어보았다. 팀 내 공유에서 반응이 좋아 공식 기능으로 선정되어 본격 개발에 들어갔다.
초기 구현은 LangChain의 todoListMiddleware와 subagentMiddleware를 그대로 활용하는 방식이었다.
하지만 실제로 운영해보니 Todo와 SubAgent 간 매핑이 휴리스틱에 의존해 불안정했다.
LangChain의 Todo 미들웨어에는 Todo↔SubAgent를 명시적으로 연결하는 필드 자체가 없었던 것이다.
이에 Plan-Based Multi-Agent Orchestration 그래프를 자체 설계했다. Plan → Orchestration → Response 3단계 LangGraph를 구성하고, Todo 생성 서비스에서 LLM이 계획 항목을 생성하면 각 Todo에 담당 SubAgent를 백엔드에서 명시적으로 할당하고, Orchestration 노드에서 단계 순으로 순차 실행, 동일 단계 내에서는 SubAgent를 병렬 실행하는 구조다. Todo–SubAgent 1:1 매핑은 도구 호출 ID를 단일 키로 사용해 매핑 오류를 원천 차단했다. 에이전트의 사고 과정과 각 단계의 진행 상태는 SSE 이벤트로 화면에 실시간 전달되어, 사용자가 "지금 AI 는 어떤 작업을 수행하고 있는지" 를 투명하게 확인할 수 있게 했다.
그리고 런칭. 오픈 첫 주 상위 100개 기업 기준으로만 1,692명의 활성 사용자가 총 15,410회 대화를 나눴다. 그 중 41.8%(6,447회) 가 Flow Search를 통해 처리되었다 — 서비스 전체에서 가장 많이 호출된 단일 기능이었다. 12월에 33건에 머물렀던 검색이, 이 숫자로 돌아왔다.
웹케시 그룹과 BGF의 전사 도입이 이루어졌고, 한솔그룹·남부발전·삼성화재 등 대기업의 도입 문의도 이어지고 있다. 6월부터 설계하고, 밤늦게까지 디버깅하며, 때로는 통째로 갈아엎기도 했던 시스템이 실제 기업들의 업무 흐름에 녹아드는 것을 보는 감격은 어떤 기술적 성취보다도 깊었다.
숫자로 돌아보는 8개월
2025년 6월 30일 첫 커밋부터 2026년 2월까지, 나는 이 프로젝트에 다음과 같은 흔적을 남겼다.
- 총 1,203개의 커밋 (전체 4,913건 중 24.5%)
- 2,140개 파일 수정, +322,857줄 작성 / -221,778줄 삭제
- 현재 코드 보유량 64,758줄 (전체 코드의 28.0%, 2위)
- Agent 모듈 핵심 기여자 1위
- 역할 비중 API 40%, Front 51% — 팀 내 가장 균형잡힌 풀스택 비중
- 야간 커밋(22시~03시) 303건 (전체의 25.2%)
- 월별 최고 기록: 9월 299개 커밋
이 숫자들이 자랑은 아니다. 다만 그만큼 이 프로젝트가 나에게 즐겁고, 진심이었다는 증거다. 네 번의 커밋 중 한 번은 밤 10시가 넘은 시간에 올렸다는 것은, 누군가에게는 야근의 기록일 수 있겠지만 나에게는 몰입의 기록이었다.
flow AI를 통해 배운 것
FLOKR에서 배운 "구조화" 는 flow AI에서도 유효했다. 에이전트 시스템의 Main/Sub Agent 분리, 미들웨어 패턴, 7노드 의도 기반 검색 파이프라인 등 결국 복잡한 문제를 다루는 핵심은 적절한 경계를 긋고 각 영역의 책임을 명확히 하는 것이었다.
FLOWIKI 에서 배운 "적정 기술" 역시 마찬가지였다. LangChain의 모든 기능을 사용하려 하기보다, 우리 서비스에 맞는 부분만 선택적으로 도입하고, 필요한 부분은 직접 구현하는 판단이 반복적으로 필요했다.
하지만 flow AI는 이전 프로젝트들과는 본질적으로 다른 차원의 배움을 안겨주었다.
첫 번째는 "부딪혀보는 용기" 다. RAG, LangChain, LangGraph, pgvector, SSE 스트리밍. 이 중 어느 것도 이전에 경험해본 적이 없었다. 하지만 공식 문서를 읽고, 프로토타입을 만들고, 부서지면 다시 만드는 과정을 반복하며 "해본 적 없다"는 것이 "할 수 없다"의 이유가 되지 않는다는 것을 체득했다.
두 번째는 "측정 기반 엔지니어링" 이다. 10월의 CPU 위기는 "감으로 코딩하는 것"의 한계를 정면으로 보여줬다. Chrome DevTools로 Flame Chart를 분석하고, 가설을 세우고, 하이브리드 렌더링이라는 해결책을 설계하고, CPU 부하와 FPS라는 수치로 결과를 검증하는 과정. 이것이 "엔지니어링" 이라는 단어의 진짜 의미라는 것을 이 경험을 통해 깨달았다.
세 번째는 "기존 코드를 부수는 결단" 이다.
11월에 나는 9월에 팀이 3개월 동안 만든 GeneralChatWorkflow 를 통째로 갈아엎었다.
2개월 동안 쌓아올린 코드를 스스로 부수는 것은 쉬운 결정이 아니었지만,
그 코드를 직접 만들고 운영해본 사람이기에 무엇이 한계이고 무엇이 필요한지를 가장 정확히 알 수 있었다.
완성은 때론 파괴에서 시작된다는 것을 배웠다.
코드베이스 전체 규모는 약 300,000+ 줄, 2,000+ 개 파일에 달한다. COCOMO 모델로 추정하면 약 131억원 규모이다. 물론 이 수치 자체보다는, 이 규모의 시스템을 함께 만들어낸 팀의 존재가 더 의미 있다. 혼자였다면 절대 불가능했을 것들을 팀과 함께 해냈다.
flow AI는 이제 시작이다. 8개월간 AI 에이전트 개발의 기본기를 다졌으니, 앞으로는 더 지능적이고, 더 가치 있는 것들을 만들어 나갈 것이다.