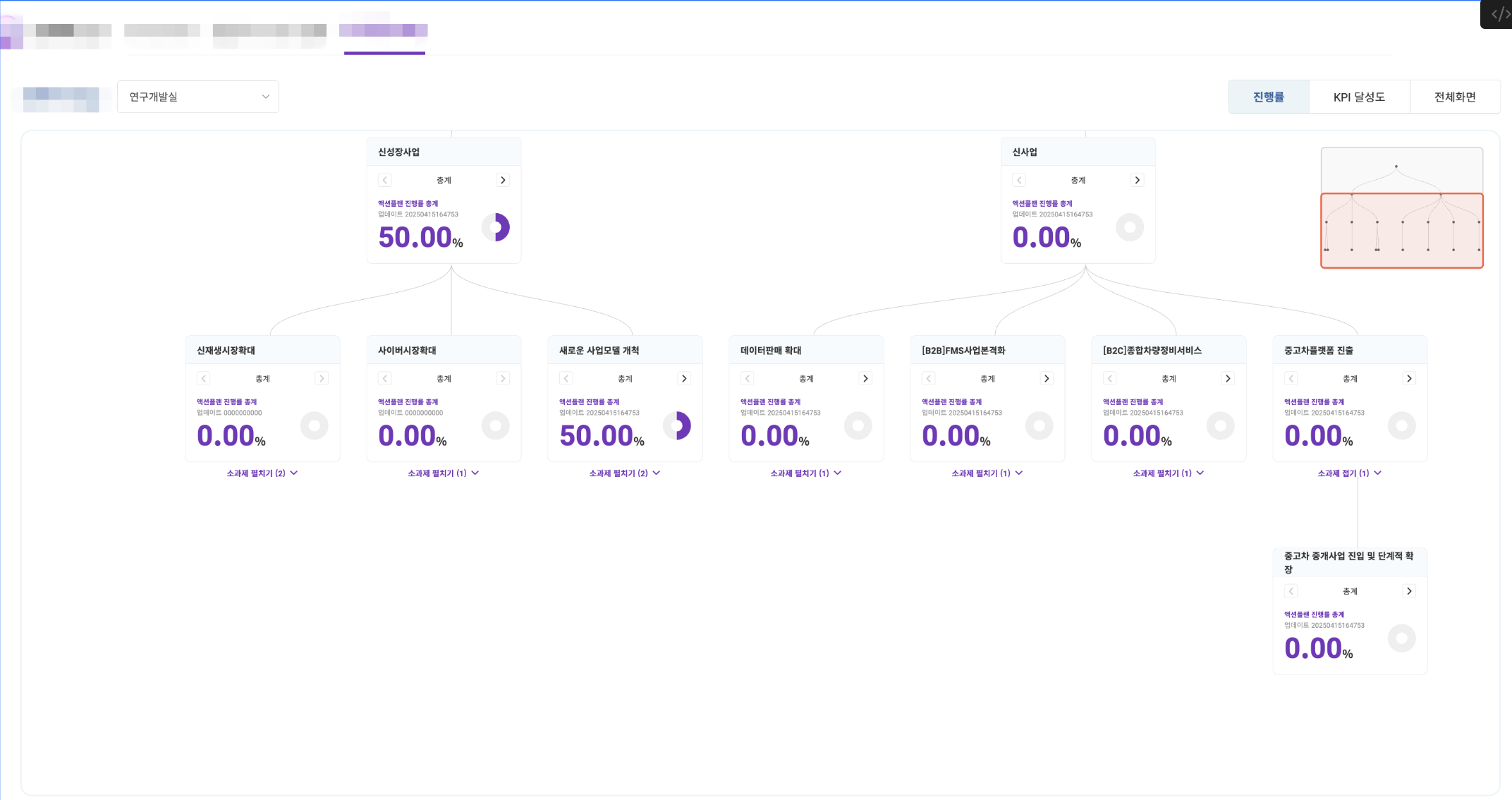
FLOKR - 대기업 보험사의 OKR 기반 성과 관리 시스템
수만 명 직원의 부문/부서별 성과를 d3.js 기반 인터랙티브 트리 다이어그램으로 시각화하는 OKR 성과 관리 시스템 개발기
FLOKR 프로젝트
FLOKR - 대기업 보험사의 OKR 기반 성과 관리 시스템
프로젝트 개요
| 항목 | 내용 |
|---|---|
| 프로젝트명 | FLOKR |
| 고객사 | 대기업 보험사 |
| 개발 기간 | 2024-10-23 ~ 2025-07-07 (약 9개월) |
| 서비스 상태 | 스테이징 배포 완료, 운영계 반영 대기중 |
1. 프로젝트 배경
조직/비즈니스 문제
- 대기업 보험사(삼성화재)의 OKR 기반 성과 관리 시스템 필요
- 기존 엑셀 기반 관리의 한계 (가시성, 실시간성 부족)
- 대규모 조직의 계층적 목표 추적 어려움
- 수만 명 직원의 부문/부서별 성과 한눈에 파악 불가
기존 시스템의 한계
- 수동적인 데이터 입력 및 집계
- 부문/부서별 성과 시각화 부재
- 권한 기반 접근 제어 미흡
- KPI 달성률 계산의 수작업 의존
2. 나의 역할
| 항목 | 내용 |
|---|---|
| 기획 참여 여부 | X (기획서 기반 개발) |
| 설계 | O (아키텍처 설계, 도메인 모델링) |
| 구현 | O (백엔드 전체, 프론트엔드 Map 시각화) |
| 운영 | 스테이징 배포 완료, 운영계 반영 대기중 |
담당 영역
1. 초격차 Map 시각화 (핵심)
- OKR 트리 구조 시각화: d3.js 기반 인터랙티브 다이어그램
- 부문별 과제-액션플랜-KPI 계층 구조 렌더링
- 미니맵 네비게이션, 줌/팬 인터랙션 구현
- 슬라이드쇼 기능 (전체 부문 순회)
2. 통합 어드민 시스템
- 전체 서비스를 관통하는 관리 시스템
- 과제/액션플랜/권한 관리 CRUD
- 엑셀 일괄 업로드/다운로드
- API 요청 이력 추적 (변경 히스토리)
3. 백엔드 전체 설계/구현
- Nest.js 기반 모듈화된 아키텍처
- Task, KPI, ActionPlan, Division, Map 도메인 설계
- Redis 캐싱 인터셉터 구현
- 권한 기반 접근 제어 (RBAC)
3. 기술 선택과 이유
Nest.js 선택 이유
- 사내 신규 프로덕트들의 표준 백엔드 프레임워크
- 로깅, 인증/인가 등 공통 로직 재사용 가능
- 모듈화된 구조로 대규모 도메인 관리 용이
- TypeScript 기반의 강타입 시스템
VanillaJS 선택 이유 (프론트엔드)
- 퍼블리싱 팀과의 협업 제약: React 등 신규 프레임워크 도입 어려움
- 기존 사내 표준 기술 스택 유지 필요
- 퍼블리싱 결과물을 그대로 적용 가능
d3.js 선택 이유 (Map 시각화)
- 대규모 트리 구조 렌더링에 최적화된 라이브러리
- SVG 기반으로 커스텀 UI 요소 삽입 가능 (foreignObject)
- Zoom/Pan 인터랙션 내장
- 계층 트리 레이아웃 알고리즘 제공 (d3.tree, d3.hierarchy)
Closure Table 선택 이유 (계층 구조 저장)
- OKR 과제의 다단계 계층 구조 (루트 과제 → 대과제 → 중과제 → 소과제) 저장 필요
- O(1) 조상/자손 쿼리: 단일 쿼리로 모든 조상 또는 자손 조회 가능
- Adjacency List의 한계 극복: 재귀 쿼리 없이 N-depth 계층 조회
- 트리 재구성 용이: depth 컬럼으로 직접 관계(depth=1)와 전체 계층 분리
Monorepo 선택 이유
- 공통 로직(로깅, 인증/인가) 재사용
- 백엔드/프론트엔드 통합 관리
- 일관된 빌드/배포 파이프라인
아키텍처 전환 (헥사고날 → 레이어드)
| 단계 | 아키텍처 | 특징 |
|---|---|---|
| 초기 | 헥사고날 | CQRS 패턴, Command/Handler 구조 |
| 전환 | 레이어드 | Controller → Service → Repository |
전환 이유:
- 프로젝트 규모 대비 과도한 복잡성
- 팀원 러닝커브 문제
- 유지보수성 우선
4. 어려웠던 지점 (핵심)
4.1 기술적 병목
트리 구조 생성 성능 (N+1 문제)
문제: 각 Task 노드마다 하위 ActionPlan, KPI를 개별 조회하면서 부문별 수백 개 노드 처리 시 심각한 성능 저하 발생
해결 - 배치 쿼리 패턴 적용:
1// 예시: In() 연산자를 활용한 배치 쿼리로 N+1 문제 해결2async findDirectRelations(nodeIdList: number[]): Promise<NodeRelation[]> {3 // N개 노드의 관계를 1번의 쿼리로 조회 (N+1 → 1)4 return await this.relationRepository.find({5 where: [6 { depth: 1, ancestor: In(nodeIdList) },7 { depth: 1, descendant: In(nodeIdList) },8 ],9 relations: ['ancestor', 'descendant'],10 });11}12
13// 예시: 조회 결과를 Map으로 변환하여 O(1) 검색 제공14async getMetricsWithRate(metricList: Metric[]): Promise<Metric[]> {15 const idList = metricList.map(m => m.id);16
17 // 모든 메트릭의 월별 데이터를 한 번에 조회18 const monthlyData = await this.monthlyRepository.find({19 where: { metricId: In(idList), period: lastMonth }20 });21
22 // Map으로 변환 → O(1) 검색23 const dataMap = new Map(24 monthlyData.map(item => [item.metricId, item])25 );26
27 // 기존 리스트에 달성률 추가28 return metricList.map(metric => ({29 ...metric,30 rate: calculateRate(dataMap.get(metric.id))31 }));32}KPI 달성률 계산 및 상향 집계
문제: 월별/연도별 목표 대비 실적 계산과 하위 노드에서 상위 노드로의 집계 로직 복잡성
해결 - 정보 상향 전파 로직:
1// 예시: 리프 노드에서 루트로 정보 전파2private propagateInfoUpwards(3 nodeMap: Map<number, TreeNode>,4 parentMap: Map<number, number>, // childId → parentId5 leafNodeIds: Set<number>,6): void {7 const propagateToAncestors = (nodeId: number): void => {8 let currentId = nodeId;9
10 // 부모가 있는 동안 계속 상위로 전파11 while (parentMap.has(currentId)) {12 const parentId = parentMap.get(currentId)!;13 const currentNode = nodeMap.get(currentId);14 const parentNode = nodeMap.get(parentId);15
16 if (!currentNode || !parentNode) break;17
18 // 중복 제거하며 메트릭 정보 상향 전파19 this.mergeMetricsToParent(currentNode, parentNode);20 currentId = parentId;21 }22 };23
24 // 모든 리프 노드에서 시작25 leafNodeIds.forEach(propagateToAncestors);26}Redis 캐싱 도입
문제: Map 데이터 조회 응답 속도 개선 필요, 캐시 무효화 전략 설계
해결 - 인터셉터 기반 캐싱 구현:
1// 예시: NestJS 캐싱 인터셉터 패턴2@Injectable()3export class CacheInterceptor implements NestInterceptor {4 async intercept(context: ExecutionContext, next: CallHandler) {5 const cacheKey = this.generateCacheKey(context);6
7 // 캐시 Hit: 즉시 반환8 const cached = await this.cacheService.get(cacheKey);9 if (cached) return of(cached);10
11 // 캐시 Miss: 요청 처리 후 결과 캐싱12 return next.handle().pipe(13 tap(async (response) => {14 await this.cacheService.set(cacheKey, response, TTL);15 }),16 );17 }18
19 // URL 기반 동적 캐시 키 생성20 private generateCacheKey(ctx: ExecutionContext): string {21 const request = ctx.switchToHttp().getRequest();22 return `cache:${encodeURIComponent(request.url)}`;23 }24}4.2 도메인 이해의 어려움
OKR 개념의 시스템화
프로젝트 초반에 가장 어려웠던 점은 OKR이라는 추상적인 개념을 코드로 표현하는 것이었다. "목표(Objective)"와 "핵심결과(Key Result)"라는 용어는 익숙했지만, 이를 과제(Task), 액션플랜(ActionPlan), KPI라는 엔티티로 모델링하는 과정에서 많은 시행착오가 있었다. 특히 "어디까지가 과제이고, 어디서부터 액션플랜인가?"라는 경계를 정하는 것이 쉽지 않았다.
결국 깨달은 것은 기술적 관점이 아닌 사람의 업무 흐름을 코드로 표현한다 는 관점으로 바라봐야 한다는 점이었다. 실제로 조직에서 목표를 설정하고, 이를 달성하기 위한 구체적인 행동 계획을 세우고, 그 성과를 측정하는 흐름 그대로를 코드에 담으니 도메인 모델이 자연스럽게 정리되었다.
대기업 조직 구조 반영
1부문(Unit)2 └── 부서(Division)3 └── 과제(Task) - 대/중/소과제4 └── 액션플랜(ActionPlan)5 └── KPI수만 명 규모의 대기업 조직 구조를 시스템에 반영하는 것도 도전이었다. 부문별 리더, 과제 담당자, 일반 사용자 등 다양한 역할이 존재했고, 각 역할마다 볼 수 있는 데이터와 수행할 수 있는 액션이 달랐다. 처음에는 이 복잡한 권한 체계를 어떻게 설계해야 할지 막막했지만, 역할 기반 접근 제어(RBAC) 패턴을 적용하면서 점차 구조가 잡혀갔다.
4.3 협업/운영 이슈
퍼블리싱 팀 협업
이 프로젝트에서 가장 큰 제약 중 하나는 VanillaJS 기술 스택이었다. React나 Vue 같은 모던 프레임워크를 사용할 수 없었던 이유는 퍼블리싱 팀과의 협업 때문이었다. 퍼블리싱 팀에서 작업한 HTML/CSS 결과물을 그대로 적용해야 했기 때문에, 프레임워크 도입은 사실상 불가능했다.
처음에는 이 제약이 불편하게 느껴졌지만, d3.js의 foreignObject를 활용하면서 해결책을 찾았다. SVG 내부에 HTML 요소를 직접 삽입할 수 있는 foreignObject 덕분에, 퍼블리싱 결과물을 거의 수정 없이 d3.js 트리 구조에 통합할 수 있었다. 제약 조건 안에서 창의적인 해결책을 찾는 경험이었다.
요구사항 변경 대응
9개월간의 개발 기간 동안 요구사항 변경은 피할 수 없었다. 통합 어드민에 권한 관리와 변경 이력 기능이 추가되었고, API 요청 이력 추적 기능도 중간에 요청되었다. 과제 엔티티에 담당자와 우대 역량 필드가 추가되기도 했다.
이런 변경들에 유연하게 대응할 수 있었던 것은 모듈화된 아키텍처 덕분이었다. 도메인별로 명확히 분리된 구조 덕분에, 새로운 기능 추가나 필드 확장이 다른 모듈에 영향을 최소화하면서 이루어졌다.
4.4 Closure Table을 활용한 계층 구조 설계
왜 Closure Table인가?
OKR 과제 시스템은 4단계 계층 구조를 가집니다:
13대 인덱스 (INDEX)2 └── 대과제 (BIG)3 └── 중과제 (MEDIUM)4 └── 소과제 (SMALL)5 └── 액션플랜 (ActionPlan)이 구조를 저장하기 위해 여러 패턴을 검토했습니다:
| 패턴 | 장점 | 단점 |
|---|---|---|
| Adjacency List | 단순, 직관적 | N-depth 조회 시 재귀 쿼리 필요 |
| Nested Set | 빠른 조회 | 삽입/삭제 시 전체 트리 재계산 |
| Materialized Path | 경로 문자열로 조회 | 문자열 파싱 필요, 인덱싱 어려움 |
| Closure Table | O(1) 조상/자손 쿼리, 유연한 트리 조작 | 저장 공간 증가 (모든 관계 저장) |
Closure Table 선택 이유:
- 읽기 작업 최적화: Map 시각화에서 부문별 전체 과제 트리를 빈번하게 조회
- depth 컬럼 활용:
depth=1로 직접 부모-자식 관계만 필터링 가능 - 유연한 트리 조작: 과제 이동/삭제 시 특정 관계만 업데이트
Closure Table 엔티티 설계
1// 예시: Closure Table 엔티티 구조2@Entity('node_closure')3export class NodeClosure extends BaseEntity {4 @PrimaryColumn({ type: 'bigint' })5 id: number;6
7 // 조상 (상위 노드)8 @ManyToOne(() => Node, node => node.ancestorRelations, { onDelete: 'CASCADE' })9 @JoinColumn({ name: 'ancestor_id' })10 ancestor: Node;11
12 // 자손 (하위 노드)13 @ManyToOne(() => Node, node => node.descendantRelations, { onDelete: 'CASCADE' })14 @JoinColumn({ name: 'descendant_id' })15 descendant: Node;16
17 // 관계 깊이: 0=자기 자신, 1=직접 부모-자식, 2=조부모-손자...18 @Column({ type: 'int' })19 depth: number;20}21
22// Node 엔티티 측 관계 정의23@Entity('node')24export class Node extends BaseEntity {25 @PrimaryColumn({ type: 'bigint' })26 id: number;27
28 // 이 노드가 조상인 모든 관계29 @OneToMany(() => NodeClosure, closure => closure.ancestor)30 ancestorRelations: NodeClosure[];31
32 // 이 노드가 자손인 모든 관계33 @OneToMany(() => NodeClosure, closure => closure.descendant)34 descendantRelations: NodeClosure[];35
36 @Column({ type: 'varchar', length: 10 })37 type: string; // ROOT, LEVEL1, LEVEL2, LEVEL338}Closure Table 데이터 예시
과제 계층이 다음과 같을 때:
1ROOT-1 (루트)2 └── L1-1 (레벨1)3 └── L2-1 (레벨2)4 └── L3-1 (레벨3)node_closure 테이블에는 모든 조상-자손 관계가 저장됩니다:
| ancestor | descendant | depth |
|---|---|---|
| ROOT-1 | ROOT-1 | 0 |
| ROOT-1 | L1-1 | 1 |
| ROOT-1 | L2-1 | 2 |
| ROOT-1 | L3-1 | 3 |
| L1-1 | L1-1 | 0 |
| L1-1 | L2-1 | 1 |
| L1-1 | L3-1 | 2 |
| L2-1 | L2-1 | 0 |
| L2-1 | L3-1 | 1 |
| L3-1 | L3-1 | 0 |
핵심 쿼리 패턴
1// 예시: 직접 부모-자식 관계만 조회 (depth=1)2async findDirectRelations(nodeIdList: number[]): Promise<NodeClosure[]> {3 return await this.closureRepository.find({4 where: [5 { depth: 1, ancestor: In(nodeIdList) }, // 직접 자식들6 { depth: 1, descendant: In(nodeIdList) }, // 직접 부모들7 ],8 relations: ['ancestor', 'descendant'],9 });10}11
12// 예시: 특정 depth의 하위 노드 집계13async getChildCountByDepth(nodeType: string, targetDepth: number) {14 return await this.nodeRepository15 .createQueryBuilder('n')16 .leftJoin('node_closure', 'nc',17 'nc.ancestor_id = n.id AND nc.depth = :depth',18 { depth: targetDepth }19 )20 .where('n.type = :type', { type: nodeType })21 .select('n.id', 'nodeId')22 .addSelect('COUNT(nc.descendant_id)', 'childCount')23 .groupBy('n.id')24 .getRawMany();25}26
27// 예시: 루트 노드의 직접 자식 목록 조회28async getDirectChildren(rootId: number): Promise<number[]> {29 const result = await this.closureRepository30 .createQueryBuilder('nc')31 .select('nc.descendant_id', 'childId')32 .where('nc.ancestor_id = :rootId', { rootId })33 .andWhere('nc.depth = 1') // 직접 자식만34 .getRawMany();35
36 return result.map(row => Number(row.childId));37}Closure Table 생성 알고리즘
엑셀 업로드 시 트리 구조를 파싱하여 Closure Table 레코드를 생성합니다:
1// 예시: Closure Table 레코드 생성 알고리즘2class TreeBuilder {3 private closureRecords: NodeClosure[] = [];4
5 // 모든 조상-자손 관계를 재귀적으로 생성6 public buildClosureTable(rootNodes: TreeNode[]): NodeClosure[] {7 this.closureRecords = [];8 for (const root of rootNodes) {9 this.traverseWithAncestors(root, []);10 }11 return this.closureRecords;12 }13
14 /**15 * 핵심 알고리즘: DFS로 트리 순회하며 모든 조상과의 관계 생성16 * ancestors: 현재까지 방문한 조상 노드 스택17 */18 private traverseWithAncestors(node: TreeNode, ancestors: TreeNode[]) {19 // 모든 조상과의 관계 생성 (depth = 조상까지의 거리)20 for (let i = 0; i < ancestors.length; i++) {21 this.addClosureRecord(22 ancestors[i], // 조상23 node, // 현재 노드 (자손)24 ancestors.length - i // depth: 거리25 );26 }27
28 // 자기 자신과의 관계 (depth=0)29 this.addClosureRecord(node, node, 0);30
31 // 재귀: 자식 노드 처리 (백트래킹 패턴)32 ancestors.push(node);33 for (const child of node.children) {34 this.traverseWithAncestors(child, ancestors);35 }36 ancestors.pop();37 }38
39 private addClosureRecord(ancestor: TreeNode, descendant: TreeNode, depth: number) {40 this.closureRecords.push({41 ancestor: { id: ancestor.id },42 descendant: { id: descendant.id },43 depth: depth,44 });45 }46}Closure Table 배치 Upsert
1// 예시: 트랜잭션 기반 배치 업데이트2async batchUpsertClosure(treeBuilder: TreeBuilder) {3 const closureData = treeBuilder.buildClosureTable();4
5 await this.dataSource.transaction(async (manager) => {6 // 기존 관계 전체 삭제 후 재생성 (Full Rebuild 전략)7 await manager.createQueryBuilder()8 .delete()9 .from(NodeClosure)10 .execute();11
12 await manager.createQueryBuilder()13 .insert()14 .into(NodeClosure)15 .values(closureData)16 .execute();17 });18}Closure Table 활용 - 트리 재구성
1// 예시: Closure Table 데이터로 메모리 트리 구축2class TreeReconstructor {3 buildTree(4 directRelations: NodeClosure[], // depth=1인 관계만 전달5 nodeMap: Map<number, TreeNode>,6 ): { leafIds: Set<number>; parentMap: Map<number, number> } {7 const leafIds = new Set<number>();8 const parentMap = new Map<number, number>();9
10 directRelations.forEach(relation => {11 const parentId = relation.ancestor.id;12 const childId = relation.descendant.id;13
14 if (parentId === childId) return; // 자기 참조(depth=0) 스킵15
16 const parentNode = nodeMap.get(parentId);17 const childNode = nodeMap.get(childId);18
19 if (!childNode || !parentNode) return;20
21 leafIds.add(childId);22 parentNode.children.push(childNode); // 메모리 트리 구축23 parentMap.set(childId, parentId);24 });25
26 return { leafIds, parentMap };27 }28}Closure Table 성능 분석
| 작업 | Adjacency List | Closure Table |
|---|---|---|
| 직접 자식 조회 | O(1) | O(1) - depth=1 필터 |
| 모든 자손 조회 | O(n) - 재귀 쿼리 | O(1) - 단일 쿼리 |
| 모든 조상 조회 | O(n) - 재귀 쿼리 | O(1) - 단일 쿼리 |
| 노드 삽입 | O(1) | O(depth) - 조상 수만큼 |
| 노드 삭제 | O(n) - 자손 처리 | O(자손 수) |
| 저장 공간 | O(n) | O(n²) - 최악의 경우 |
FLOKR에서의 선택 이유:
- Map 시각화에서 읽기 작업이 압도적으로 많음
- 과제 구조는 엑셀 배치 업로드로 일괄 생성 (쓰기 작업 빈도 낮음)
- 4단계 고정 계층으로 저장 공간 증가 제한적
5. 해결 방식
5.1 구조적 선택
도메인 분리
1modules/2├── task/ # 과제 도메인3├── kpi/ # 성과지표 도메인4├── action-plan/ # 액션플랜 도메인5├── division/ # 부서/부문 도메인6├── map/ # Map 시각화 도메인7├── admin-master/ # 통합 어드민 도메인8└── ...트리 구조 생성 핵심 로직
1// 예시: 트리 생성 프로세스 (3단계)2class HierarchyBuilder {3 build(options: BuildOptions): TreeNode[] {4 // 1. 부모-자식 관계 맵 구축 및 부가정보 매핑5 const { leafIds, parentMap } = this.buildRelationMaps(6 options.directRelations,7 options.nodeMap8 );9
10 // 2. 리프 노드에서 상위 부모로 정보 집계11 this.propagateInfoUpwards(options.nodeMap, parentMap, leafIds);12
13 // 3. 루트 직속 하위 노드 추출14 return this.extractChildren(options.nodeMap, leafIds);15 }16
17 // 부모-자식 관계 구축 (O(n) 성능)18 private buildRelationMaps(19 relations: NodeRelation[],20 nodeMap: Map<number, TreeNode>,21 ): { leafIds: Set<number>; parentMap: Map<number, number> } {22 const leafIds = new Set<number>();23 const parentMap = new Map<number, number>();24
25 relations.forEach(relation => {26 const parentId = relation.ancestor.id;27 const childId = relation.descendant.id;28
29 if (parentId === childId) return; // 순환 참조 방지30
31 const parentNode = nodeMap.get(parentId);32 const childNode = nodeMap.get(childId);33
34 if (!childNode || !parentNode) return;35
36 leafIds.add(childId);37 parentNode.children.push(childNode);38 parentMap.set(childId, parentId);39 });40
41 return { leafIds, parentMap };42 }43
44 // 루트 노드 추출 (부모가 없는 노드)45 private extractChildren(46 nodeMap: Map<number, TreeNode>,47 leafIds: Set<number>48 ): TreeNode[] {49 return Array.from(nodeMap.entries())50 .filter(([id]) => !leafIds.has(id))51 .flatMap(([, node]) => node.children);52 }53}권한 데코레이터
1// 예시: 역할 기반 접근 제어 패턴2export enum AuthLevel {3 ADMIN = 'ADMIN',4 VIEW = 'VIEW',5 EDIT = 'EDIT',6 EXPORT = 'EXPORT',7}8
9export const ROLES_KEY = 'roles';10export const RequireRoles = (...roles: AuthLevel[]) =>11 SetMetadata(ROLES_KEY, roles);12
13// Guard 구현14@Injectable()15export class RoleGuard implements CanActivate {16 async canActivate(context: ExecutionContext): Promise<boolean> {17 const requiredRoles = this.reflector.getAllAndOverride<AuthLevel[]>(18 ROLES_KEY,19 [context.getHandler(), context.getClass()]20 );21
22 if (!requiredRoles) return true;23
24 const request = context.switchToHttp().getRequest();25 const user = request.user;26
27 // OR 조건으로 권한 확인28 const hasRole = user.roles.some(role => requiredRoles.includes(role));29 if (!hasRole) {30 throw new ForbiddenException('권한이 없습니다');31 }32
33 return true;34 }35}5.2 트레이드오프
| 결정 | 선택 | 대안 | 이유 |
|---|---|---|---|
| 아키텍처 | 레이어드 | 헥사고날 | 복잡성 vs 유지보수성 |
| 캐싱 | Redis | 인메모리 | 확장성 vs 단순성 |
| 프론트 | VanillaJS | React | 퍼블 협업 vs 생산성 |
| 시각화 | d3.js | Chart.js | 커스텀 vs 편의성 |
6. 결과와 남은 것
6.1 서비스 상태
- 스테이징 배포 완료
- 운영계 반영 대기중
- QA 진행 및 버그 수정 완료
6.2 재사용 가능한 패턴
계층 구조 생성 클래스
1// 트리 구조 생성 공통 패턴2const builder = new HierarchyBuilder(nodeList, relations, additionalInfo);3const rootNodes = builder.build();Redis 캐싱 인터셉터
1@UseInterceptors(CacheInterceptor)2@Get('/map/data')3async getMapData() { ... }API 요청 이력 추적
1@AuditLog({ action: 'UPDATE' })2@Patch('/resource/:id')3async updateResource() { ... }권한 관리 체계
1@UseGuards(RoleGuard)2@RequireRoles(AuthLevel.ADMIN)6.3 나의 사고 방식 변화
이 프로젝트를 통해 가장 크게 달라진 것은 "기술보다 도메인을 먼저 이해해야 한다"는 인식이다. 예전에는 어떤 프레임워크를 쓸지, 어떤 패턴을 적용할지부터 고민했다면, 이제는 "이 시스템이 해결하려는 문제가 무엇인가?"를 먼저 질문하게 되었다.
특히 사람의 업무 흐름을 코드로 표현한다 는 관점은 이 프로젝트에서 얻은 가장 중요한 통찰이다. OKR이라는 추상적인 개념을 시스템화하면서 깨달은 것은, 결국 좋은 소프트웨어란 사용자의 실제 업무 방식을 자연스럽게 반영하는 것이라는 점이었다.
또한 적정 기술 선택의 중요성도 배웠다. 프로젝트 초기에 헥사고날 아키텍처를 도입했다가 레이어드로 전환한 경험은, 과도한 추상화가 오히려 팀의 생산성을 떨어뜨릴 수 있다는 교훈을 주었다. 완벽한 설계를 추구하기보다 동작하는 시스템을 먼저 만들고, 필요에 따라 점진적으로 개선해 나가는 접근이 현실적으로 더 효과적이라는 것을 몸소 체험했다.
핵심 구현 (예시 샘플 코드)
A. 초격차 Map 시각화
핵심 구현 - Map 생성 서비스
1// 예시: 부문 코드 기반 Map 생성 흐름2async generateMap(unitCode: string, mapType: MapType): Promise<MapData> {3 // 1. 부문 정보 조회4 const unit = await this.unitService.getByCode(unitCode);5 const divisionCodes = unit.divisions.map(d => d.code);6
7 // 2. 부서와 매핑된 노드 리스트 조회 (배치)8 let nodeList = await this.nodeService.findByDivisions(divisionCodes);9
10 // 3. Fallback: 노드가 없으면 유효한 부문의 노드 조회11 if (nodeList.length === 0) {12 nodeList = await this.findValidUnitNodes();13 }14
15 // 4. 노드 트리 생성16 const treeData = await this.buildNodeTree(nodeList, mapType);17
18 return MapData.of({19 unitName: unit.name,20 unitCode: unit.code,21 children: treeData,22 });23}24
25// 노드 리스트를 트리 구조로 변환26async buildNodeTree(nodeList: Node[], mapType: MapType) {27 const nodeIdList = nodeList.map(n => n.id);28
29 // 배치 쿼리: 직접적 부모-자식 관계만 조회 (N+1 방지)30 const directRelations = await this.nodeService.findDirectRelations(nodeIdList);31
32 // 부가정보를 타입에 따라 조회33 const additionalInfo = await this.getAdditionalInfo(nodeIdList, mapType);34
35 // HierarchyBuilder를 통해 계층 구축36 const builder = new HierarchyBuilder(nodeList, directRelations, additionalInfo);37 return builder.build();38}d3.js 시각화 핵심 구현
1// 예시: d3.js 트리 시각화 핵심 구조2import * as d3 from 'd3';3
4function renderTreeMap(treeData, options = {}) {5 const { width, height } = getDimensions();6
7 // SVG 초기화8 const svg = initializeSvg(width, height);9
10 // d3.hierarchy: JSON을 계층 구조로 변환11 const root = d3.hierarchy(treeData);12
13 // 노드 간 간격 정의 (타입별 분기)14 const separation = (a, b) => {15 return (a.data.type === 'LEAF' || b.data.type === 'LEAF')16 ? CONFIG.MIN_SEPARATION17 : CONFIG.DEFAULT_SEPARATION;18 };19
20 // d3.tree: 트리 레이아웃 설정 및 좌표 계산21 const treeLayout = d3.tree()22 .nodeSize([CONFIG.NODE_WIDTH, CONFIG.NODE_HEIGHT])23 .separation(separation);24 treeLayout(root);25
26 // 메인 그룹 요소27 const g = svg.append("g");28
29 // 트리 렌더링30 renderNodes(g, root, options);31 renderLinks(g, root);32
33 // 미니맵 생성34 createMiniMap(svg, g, root, { width, height });35
36 // 줌 설정37 initializeZoom(svg, g);38}d3.js 노드 렌더링 - foreignObject 활용
1// 예시: SVG foreignObject를 통해 HTML 삽입2function renderNodes(g, root, options) {3 // 노드 그룹에 데이터 바인딩4 const nodes = g.selectAll(".node")5 .data(root.descendants(), d => d.data.id);6
7 const nodeEnter = nodes.enter()8 .append("g")9 .attr("class", d => getNodeClass(d.depth));10
11 // 위치 변환 적용12 nodes.merge(nodeEnter)13 .attr("transform", d => `translate(${d.x},${d.y})`);14
15 // foreignObject: SVG 내에 HTML 요소 삽입16 // → 복잡한 카드 UI를 퍼블리싱 결과물 그대로 사용 가능17 nodeEnter.filter(d => d.depth > 0)18 .append("foreignObject")19 .attr("width", CONFIG.NODE_WIDTH)20 .attr("height", CONFIG.NODE_HEIGHT)21 .html(d => renderNodeTemplate(d.data));22}d3.js 미니맵 구현
1// 예시: 미니맵 네비게이션2function createMiniMap(svg, mainG, root, dimensions) {3 const { width, height } = dimensions;4 const miniMapWidth = 200;5 const miniMapHeight = 150;6
7 // 미니맵 위치 (우측 상단)8 const miniMapX = width - miniMapWidth - 20;9 const miniMapY = 20;10
11 // 트리 전체 영역 계산12 const allNodes = root.descendants();13 const bounds = calculateBounds(allNodes);14
15 // 미니맵 스케일 계산16 const scale = Math.min(17 miniMapWidth / bounds.width,18 miniMapHeight / bounds.height19 );20
21 // 미니맵 컨테이너22 const miniMapG = svg.append("g")23 .attr("class", "minimap")24 .attr("transform", `translate(${miniMapX}, ${miniMapY})`);25
26 // 배경27 miniMapG.append("rect")28 .attr("width", miniMapWidth)29 .attr("height", miniMapHeight)30 .attr("fill", "#f9f9f9")31 .attr("stroke", "#ccc");32
33 // 노드를 원으로 표시34 miniMapG.selectAll(".mini-node")35 .data(allNodes)36 .enter()37 .append("circle")38 .attr("cx", d => (d.x - bounds.minX) * scale)39 .attr("cy", d => (d.y - bounds.minY) * scale)40 .attr("r", 4)41 .attr("fill", "#666");42
43 // 뷰포트 표시기 (현재 보이는 영역)44 const viewport = miniMapG.append("rect")45 .attr("class", "viewport")46 .attr("stroke", "#FF5733")47 .attr("fill", "rgba(255, 87, 51, 0.1)");48
49 // 줌 이벤트와 연동50 svg.on("zoom.minimap", () => updateViewport(viewport, scale));51}d3.js 시각화 핵심 기술 요약
- d3.hierarchy: 백엔드 JSON을 계층 구조로 변환
- d3.tree: 트리 레이아웃 알고리즘으로 x, y 좌표 계산
- foreignObject: SVG 내에 HTML 삽입 (퍼블리싱 결과물 활용)
- d3.zoom: Zoom & Pan 인터랙션
- 미니맵 네비게이션: 전체 트리 구조 파악 및 빠른 이동
B. 통합 어드민 시스템
핵심 구현 - 배치 Upsert 패턴
1// 예시: 배치 업데이트 (Conflict resolution 패턴)2async batchUpsert(dataModels: DataModel[]) {3 await this.dataSource.transaction(async (manager) => {4 await manager5 .createQueryBuilder()6 .insert()7 .into(Entity)8 .values(dataModels)9 .orUpdate(10 ['field1', 'field2', 'updated_at'], // 업데이트할 컬럼11 ['unique_key'], // Conflict 판단 키12 )13 .execute();14 });15}16
17// 예시: 복합 키 기반 Upsert18async monthlyDataUpsert(monthlyModels: MonthlyData[]): Promise<void> {19 await this.dataSource.transaction(async (manager) => {20 await manager21 .createQueryBuilder()22 .insert()23 .into(MonthlyEntity)24 .values(monthlyModels)25 .orUpdate(26 ['value', 'rate', 'updated_by', 'updated_at'],27 ['entity_id', 'period'], // 복합 키로 conflict resolution28 )29 .execute();30 });31}핵심 러닝 포인트
기술적 성장
이 프로젝트에서 가장 큰 기술적 성장은 d3.js를 활용한 복잡한 트리 시각화 구현이었다. 단순히 라이브러리를 사용하는 것을 넘어, foreignObject를 활용해 SVG와 HTML을 결합하고, 미니맵 네비게이션까지 구현하면서 데이터 시각화에 대한 깊은 이해를 얻었다.
Closure Table 패턴은 계층 구조 저장에 대한 시야를 넓혀주었다. Adjacency List, Nested Set, Materialized Path 등 다양한 패턴을 비교 검토하면서, 각 패턴의 장단점과 적합한 사용 시나리오를 이해하게 되었다. 결국 읽기 작업이 많은 Map 시각화의 특성에 맞게 Closure Table을 선택했고, 이 과정에서 "요구사항에 맞는 기술 선택"의 중요성을 다시 한번 느꼈다.
성능 최적화 측면에서는 N+1 쿼리 문제 해결과 Redis 캐싱 인터셉터 구현 경험이 값졌다. 특히 배치 쿼리 패턴과 Map 자료구조를 활용한 O(1) 검색 최적화는 앞으로도 자주 활용할 수 있는 패턴이 되었다.
도메인 이해
기술적인 성장만큼 중요했던 것은 도메인에 대한 깊은 이해였다. OKR이라는 성과 관리 방법론을 시스템으로 구현하면서, 추상적인 비즈니스 개념을 구체적인 코드로 표현하는 능력을 키울 수 있었다. 부문(Unit)과 부서(Division)의 계층 관계, 과제와 액션플랜의 관계, KPI 달성률 계산 로직 등 복잡한 도메인 로직을 다루면서 "도메인 주도 설계"의 필요성을 몸소 체험했다.
협업 및 운영
VanillaJS라는 기술 스택 제약 속에서 퍼블리싱 팀과 협업한 경험은, 제약 조건 안에서 창의적인 해결책을 찾는 훈련이 되었다. 또한 9개월간의 개발 기간 동안 수차례의 요구사항 변경에 대응하면서, 유연한 아키텍처 설계의 중요성과 점진적 개선의 가치를 배웠다. 완벽한 설계를 처음부터 만들려고 하기보다, 변화에 열린 구조를 만들고 필요에 따라 개선해 나가는 것이 실무에서는 더 현실적인 접근이라는 것을 깨달았다.